 3 years ago
229
3 years ago
229
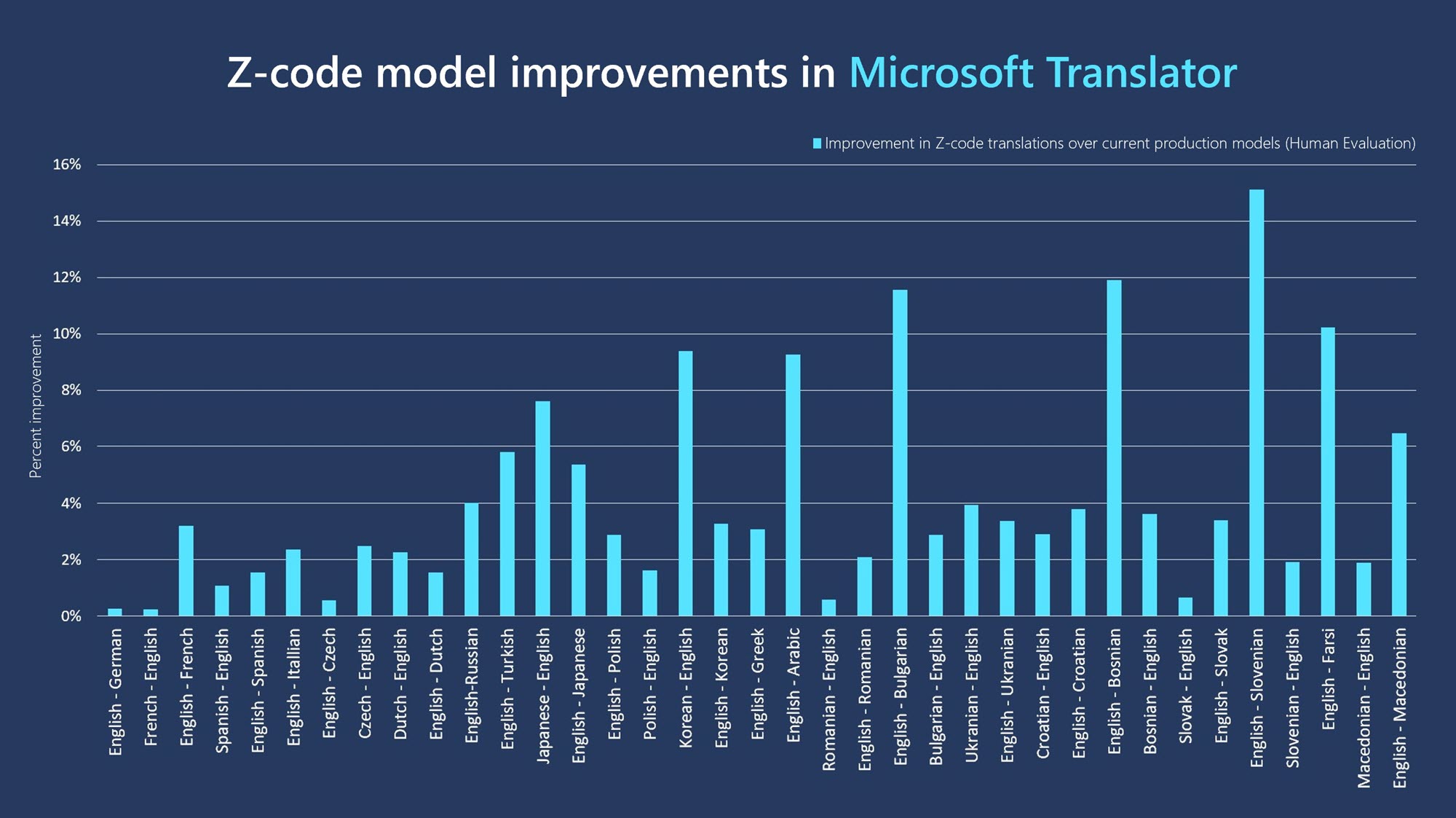
Microsoft today announced an update to its translation services that, thanks to new machine learning techniques, promises significantly improved translations between a large number of language pairs. Based on its Project Z-Code, which uses a “spare Mixture of Experts” approach, these new models now often score between 3% and 15% better than the company’s previous models during blind evaluations. Z-Code is part of Microsoft’s wider XYZ-Code initiative that looks at combining models for text, vision and audio across multiple languages to create more powerful and helpful AI systems.
“Mixture of Experts” isn’t a completely new technique, but it’s especially useful in the context of translation. At its core, the system basically breaks down tasks into multiple subtasks and then delegates them to smaller, more specialized models called “experts.” The model then decides which task to delegate to which expert, based on its own predictions. Greatly simplified, you can think of it as a model that includes multiple more specialized models.
A new class of Z-Code Mixture of Experts models are powering performance improvements in Translator, a Microsoft Azure Cognitive Service. Image Credits: Microsoft
“With Z-Code we are really making amazing progress because we are leveraging both transfer learning and multitask learning from monolingual and multilingual data to create a state-of-the-art language model that we believe has the best combination of quality, performance and efficiency that we can provide to our customers,” said Xuedong Huang, Microsoft technical fellow and Azure AI chief technology officer.
The result of this is a new system that can now, for example, directly translate between 10 languages, which eliminates the need for multiple systems. Microsoft also recently started using Z-Code models to improve other features of its AI systems, including for entity recognition, text summarization, custom text classification and keyphrase extraction. This is the first time it has used this approach for a translation service, though.
Traditionally, translation models are extremely large, making it hard to bring them into a production environment. The Microsoft team has opted for a “sparse” approach, though, which only activates a small number of model paramters per task instead of the whole system. “That makes them much more cost-efficient to run, in the same way that it’s cheaper and more efficient to only heat your house in winter during the times of day that you need it and in the spaces that you regularly use, rather than keeping a furnace running full blast all the time,” the team explains in today’s announcement.














 English (US) ·
English (US) ·