 2 years ago
186
2 years ago
186
When OctoML launched in 2019, its primary focus was optimizing machine learning (ML) models. Since then, the company has added features that make it easier to deploy ML models (and raised $132 million). Today, the company is launching the latest iteration of its service — and while it’s not quite a pivot, it does shift the company’s emphasis from optimizing models to helping businesses use existing open-source models and fine-tune them with their own data or use the service to host their own custom models. The new OctoML platform — dubbed OctoAI — is a self-optimizing compute service for AI, with a special emphasis on generative AI, that helps businesses build ML-based applications and put them into production without having to worry about the underlying infrastructure.
“The previous platform was focused on ML engineers and optimizing and packaging the models into containers that could be deployed across different sets of hardware,” OctoML co-founder and CEO Luis Ceze explained. “We learned a ton from that, but the next natural evolution is to have a fully managed compute service that abstracts all of that [ML infrastructure] away.”
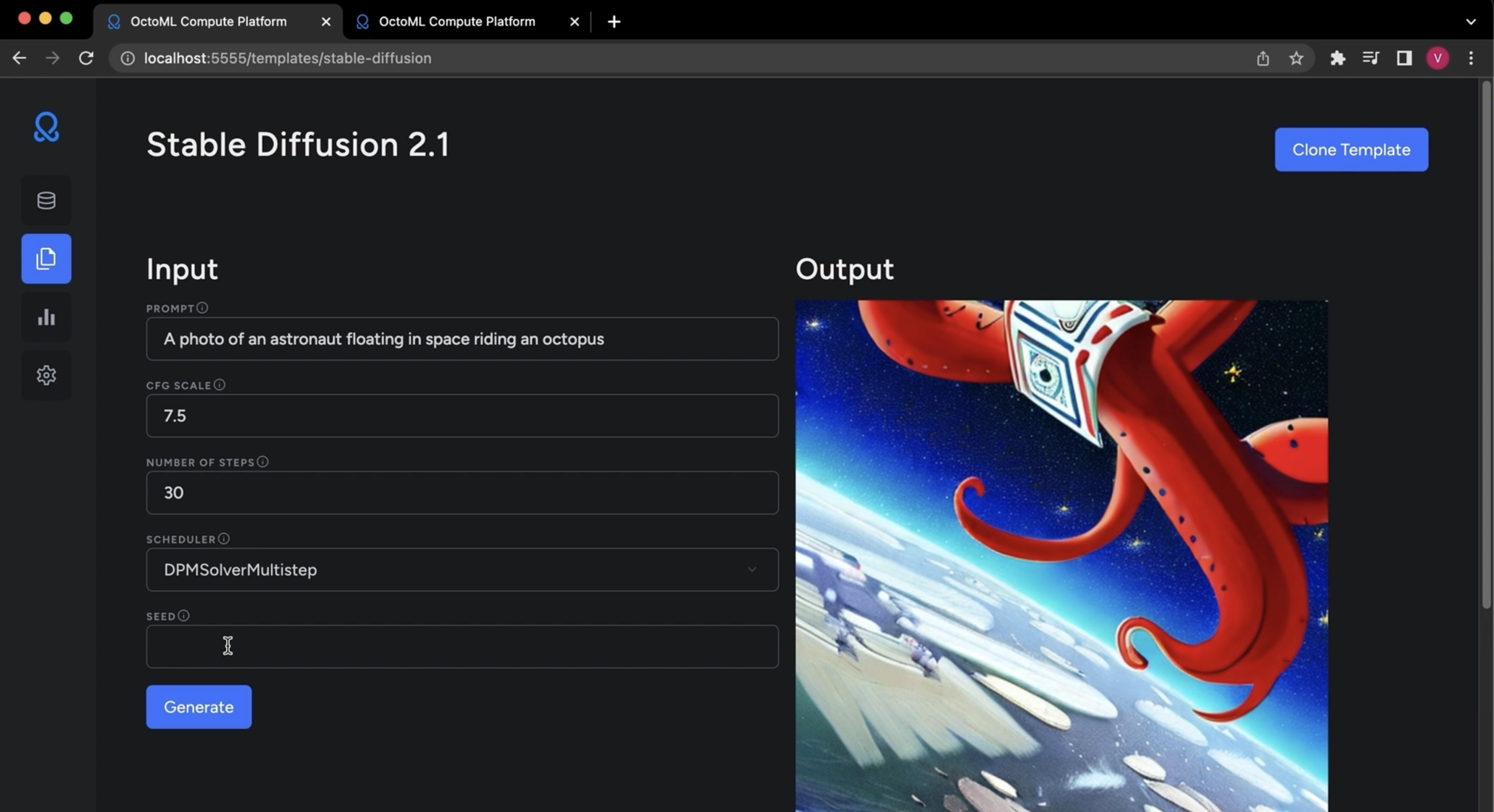
Image Credits: OctoML
With OctoAI, users simply decide what they want to prioritize (think latency vs. cost) and OctoAI will automatically choose the right hardware for them. The service will also automatically optimize these models (leading to additional cost savings and performance gains) and decide whether it’s best to run them on Nvidia GPUs or AWS’s Inferentia machines. This takes away a lot of the complexity of putting models into production, something that is still often a roadblock for many ML projects. Users who want to get full control over how their models run can, of course, also set their own parameters and decide which hardware they should run on. Ceze, however, believes that most users will opt to let OctoAI manage all of this for them.

Image Credits: OctoML
It also helps that OctoML offers accelerated versions of popular foundation models like Dolly 2, Whisper, FILM, FLAN-UL2 and Stable Diffusion out of the box, with more models on the way. OctoML managed to make Stable Diffusion run three times faster and reduce the cost by 5x when compared to running the vanilla model.
It’s worth noting that while OctoML will continue to work with existing customers who only want to use the service for optimizing their models, the company’s focus going forward will be on this new compute platform.
OctoML launches OctoAI, a self-optimizing compute service for AI by Frederic Lardinois originally published on TechCrunch














 English (US) ·
English (US) ·