 2 years ago
245
2 years ago
245
Stability AI, the startup funding a range of generative AI experiments, has released a new version of Stable Diffusion, the text-to-image AI system that was among the first to rival OpenAI’s DALL-E 2.
Called Stable Diffusion XL, or SDXL, the new system — which is available in beta through DreamStudio, Stability AI’s generative art tool — improves upon the original in key ways. Tom Mason, Stability AI’s CTO, says that it brings a “richness” to image generation that the old model (Stable Diffusion 2.1) lacked, with improvements most notable in applications like graphic design and architecture.
“We’re excited to announce the latest iteration in our Stable Diffusion series of image solutions,” he said in a canned statement. “[It’s] transformative across several industries … with the results taking place in front of our eyes.”
Setting aside the hyperbole, SDXL does indeed seem on a par with — and perhaps even better than — the latest release of MIdJourney’s model, the model responsible for “Balenciaga Pope” (among other memes).
While the previous version of Stable Diffusion and many other text-to-image systems struggle mightily to recreate certain anatomy, like hands, SDXL has no such trouble. The hands aren’t always… well, realistic. But they’re miles ahead of the nightmare fuel SDXL’s predecessor would often produce.
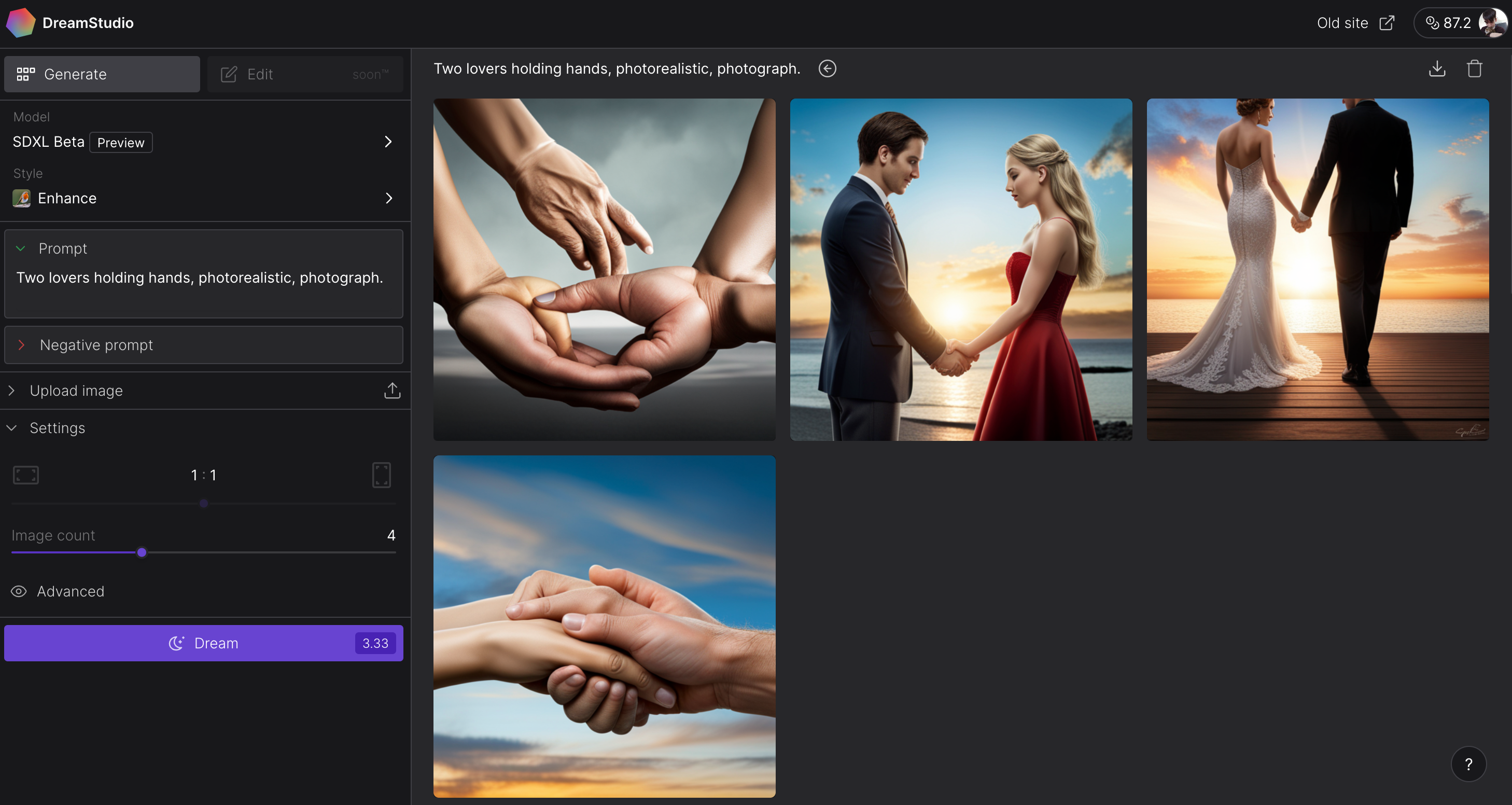
SDXL handles hands better, but obviously not perfectly.
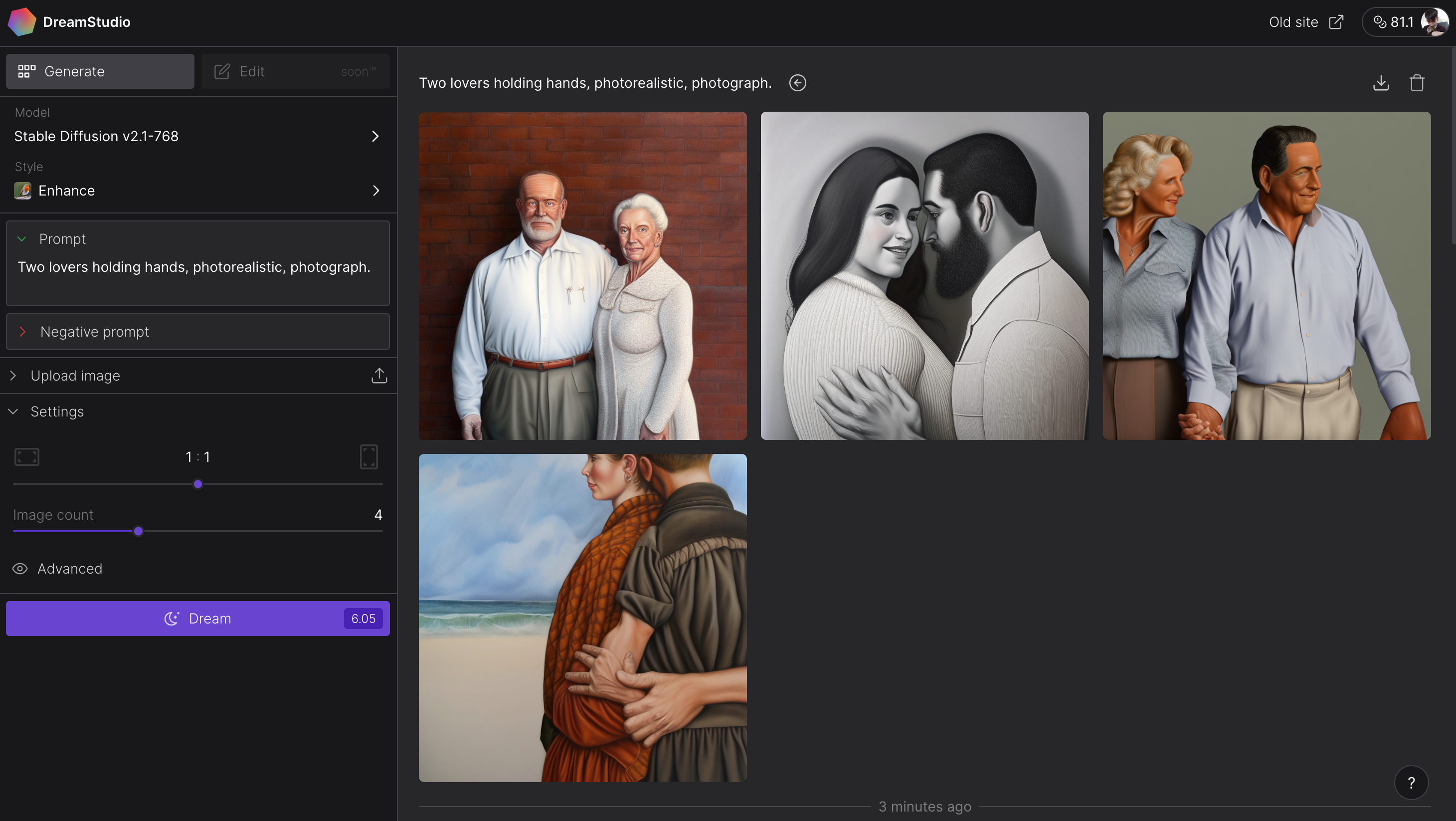
Stable Diffusion 2.1 is clearly worse at hands, hands down. (I’ll see myself out.)
SDXL is supposedly better at generating text, too, a task that’s historically thrown generative AI art models for a loop. But it still has a ways to go if my brief testing is any indication,
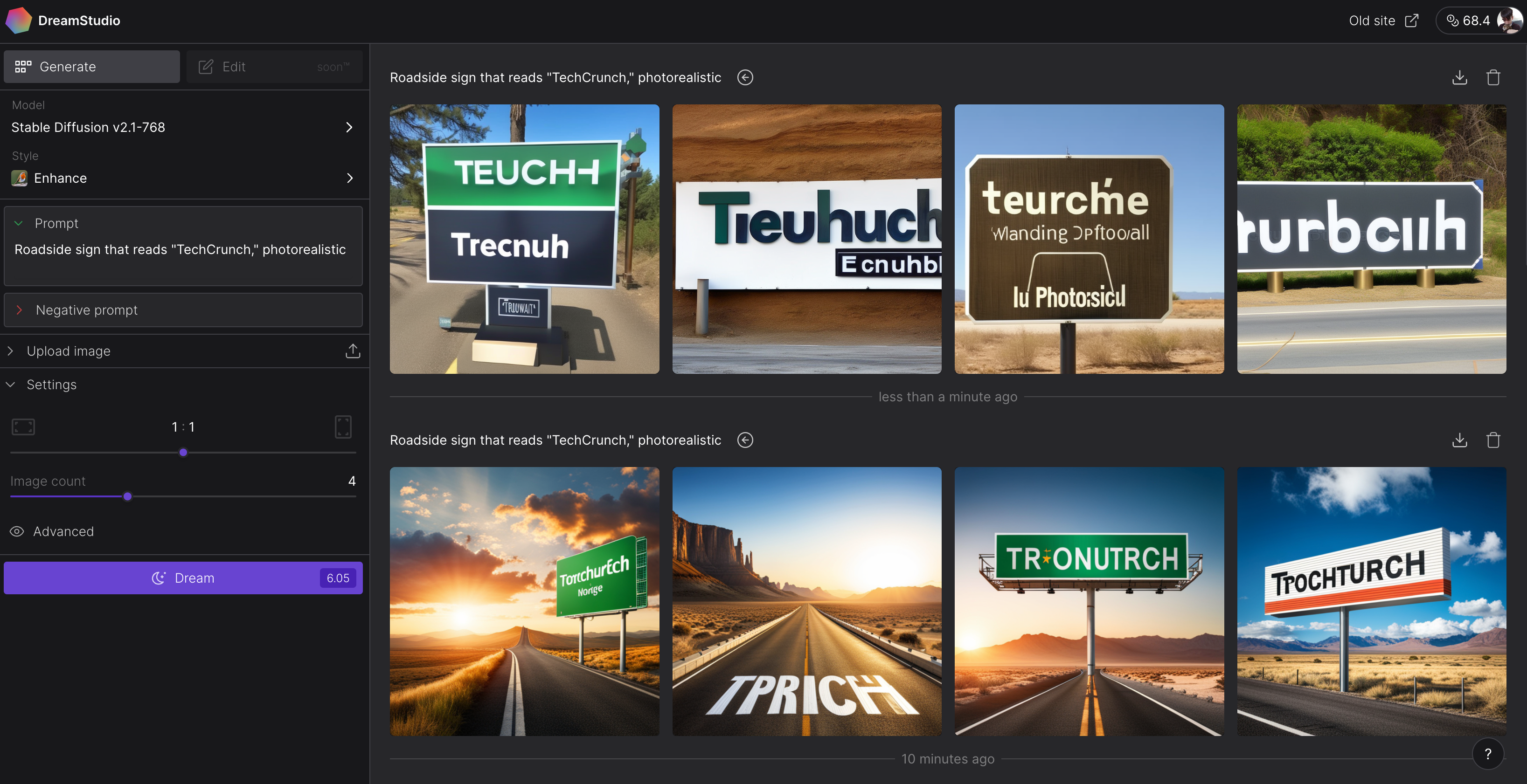
On the top, results from Stable Diffusion 2.1. On the bottom, outputs from SDXL.
In a press release, Stability AI also claims that SDXL features “enhanced image composition and face generation” and doesn’t require long, detailed prompts to create “descriptive imagery,” unlike its predecessor. Moreover, SDXL has functionality that extends beyond just text-to-image prompting, including image-to-image prompting (inputting one image to get variations of that image), inpainting (reconstructing missing parts of an image) and outpainting (constructing a seamless extension of an existing image).
As a wildcard, I tried to recreate the Balenciaga Pope meme with as short a prompt as possible: “Balenciaga Pope”. The difference in the results was starker than I expected, I must say, with SDXL posing runway models in what might pass for designer attire versus the straightforwardly religious-seeming apparel that the old Stable Diffusion conjured up.
Once it exits beta, SDXL will be open-sourced, Stability AI says, just like the previous iterations of Stable Diffusion. In addition to DreamStudio, SDXL is currently available through Stability’s API, also in early access.
While generative AI art tech marches forward, tools like SDXL have landed companies in hot water over the way they’ve been built and commercialized. Stability AI is in the crosshairs of a legal case that alleges the company infringed on the rights of millions of artists by developing its tools using web-scraped, copyrighted images. Stock image supplier Getty Images has also taken Stability AI to court for reportedly using images from its site without permission to create the original Stable Diffusion.
The open source release of Stable Diffusion has also become the subject of controversy, owing to its relatively light usage restrictions. Some communities around the web have tapped it to generate pronographic celebrity deepfakes and graphic depictions of violence. To date, at least one U.S. lawmaker has called for regulation to address the release of models like Stable Diffusion that “don’t sufficiently moderate content.”
In response to the lawsuits, Stability AI recently pledged to respect artists’ requests to remove their art from Stable Diffusion’s training data set, but that didn’t apply to SDXL — only the next-generation Stable Diffusion models, code-named “Stable Diffusion 3.0.” Artists have removed more than 78 million works of art from the training data set to date, according to Spawning, the organization leading the opt-out effort.
Legal challenges be damned, Stability AI is under pressure to monetize its sprawling AI efforts, which run the gamut from art and animation to biomed and generative audio. Stability AI CEO Emad Mostaque has hinted at plans to IPO, but Semafor recently reported that Stability AI — which raised over $100 million in venture capital last October at a reported valuation of more than $1 billion — “is burning through cash and has been slow to generate revenue,”
Stability AI’s new model is slightly better at generating hands by Kyle Wiggers originally published on TechCrunch














 English (US) ·
English (US) ·