 3 years ago
275
3 years ago
275
Benchmarks are as important a measure of progress in AI as they are for the rest of the software industry. But when the benchmark results come from corporations, secrecy very often prevents the community from verifying them.
For example, OpenAI granted Microsoft, with which it has a commercial relationship, the exclusive licensing rights to its powerful GPT-3 language model. Other organizations say that the code they use to develop systems is dependent on impossible-to-release internal tooling and infrastructure or uses copyrighted data sets. While motivations can be ethical in nature — OpenAI initially declined to release GPT-2, GPT-3’s predecessor, out of concerns that it might be misused — by the effect is the same. Without the necessary code, it’s far harder for third-party researchers to verify an organization’s claims.
“This isn’t really a sufficient alternative to good industry open-source practices,” Columbia computer science Ph.D. candidate Gustaf Ahdritz told TechCrunch via email. Ahdritz is one of the lead developers of OpenFold, an open source version of DeepMind’s protein structure-predicting AlphaFold 2. “It’s difficult to do all of the science one might like to do with the code DeepMind did release.”
Some researchers go so far as to say that withholding a system’s code “undermines its scientific value.” In October 2020, a rebuttal published in the journal Nature took issue with a cancer-predicting system trained by Google Health, the branch of Google focused on health-related research. The coauthors noted that Google withheld key technical details including a description of how the system was developed, which could significantly impact its performance.
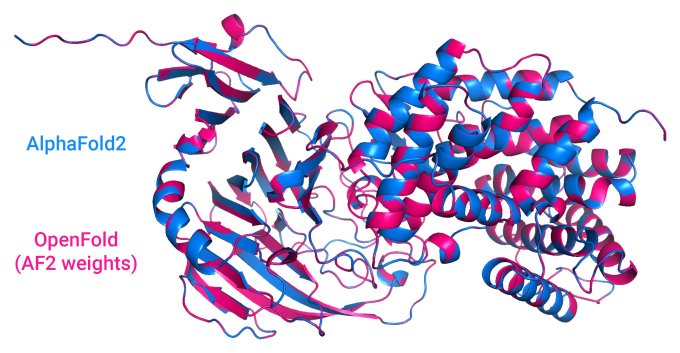
Image Credits: OpenFold
In lieu of change, some members of the AI community, like Ahdritz, have made it their mission to open source the systems themselves. Working from technical papers, these researchers painstakingly try to recreate the systems, either from scratch or building on the fragments of publicly available specifications.
OpenFold is one such effort. Begun shortly after DeepMind announced AlphaFold 2, the goal is to verify that AlphaFold 2 can be reproduced from scratch and make available components of the system that might be useful elsewhere, according to Ahdritz.
“We trust that DeepMind provided all the necessary details, but … we don’t have [concrete] proof of that, and so this effort is key to providing that trail and allowing others to build on it,” Ahdritz said. “Moreover, originally, certain AlphaFold components were under a non-commercial license. Our components and data — DeepMind still hasn’t published their full training data — are going to be completely open-source, enabling industry adoption.”
OpenFold isn’t the only project of its kind. Elsewhere, loosely-affiliated groups within the AI community are attempting implementations of OpenAI’s code-generating Codex and art-creating DALL-E, DeepMind’s chess-playing AlphaZero, and even AlphaStar, a DeepMind system designed to play the real-time strategy game StarCraft 2. Among the more successful are EleutherAI and AI startup Hugging Face’s BigScience, open research efforts that aim to deliver the code and datasets needed to run a model comparable (though not identical) to GPT-3.
Philip Wang, a prolific member of the AI community who maintains a number of open source implementations on GitHub, including one of OpenAI’s DALL-E, posits that that open-sourcing these systems reduces the need for researchers to duplicate their efforts.
“We read the latest AI studies, like any other researcher in the world. But instead of replicating the paper in a silo, we implement it open source,” Wang said. “We are in an interesting place at the intersection of information science and industry. I think open source is not one-sided and benefits everybody in the end. It also appeals to the broader vision of truly democratized AI not beholden to shareholders.”
Brian Lee and Andrew Jackson, two Google employees, worked together to create MiniGo, a replication of AlphaZero. While not affiliated with the official project, Lee and Jackson — being at Google, DeepMind’s initial parent company — had the advantage of access to certain proprietary resources.
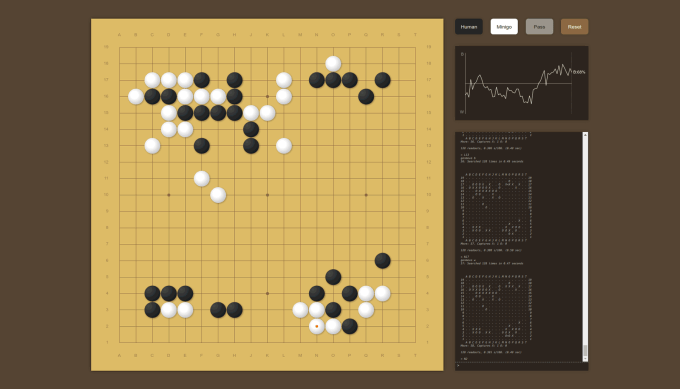
Image Credits: MiniGo
“[Working backward from papers is] like navigating before we had GPS,” Lee, a research engineer at Google Brain, told TechCrunch via email. “The instructions talk about landmarks you ought to see, how long you ought to go in a certain direction, which fork to take at a critical juncture. There’s enough detail for the experienced navigator to find their way, but if you don’t know how to read a compass, you’ll be hopelessly lost. You won’t retrace the steps exactly, but you’ll end up in the same place.”
The developers behind these initiatives, Ahdritz and Jackson included, say that they’ll not only help to demonstrate whether the systems work as advertised but enable new applications and better hardware support. Systems from large labs and companies like DeepMind, OpenAI, Microsoft, Amazon, and Meta are typically trained on expensive, proprietary datacenter servers with far more compute power than the average workstation, adding to the hurdles of open-sourcing them.
“Training new variants of AlphaFold could lead to new applications beyond protein structure prediction, which is not possible with DeepMind’s original code release because it lacked the training code — for example, predicting how drugs bind proteins, how proteins move, and how proteins interact with other biomolecules,” Ahdritz said. “There are dozens of high-impact applications that require training new variants of AlphaFold or integrating parts of AlphaFold into larger models, but the lack of training code prevents all of them.”
“These open-source efforts do a lot to disseminate the “working knowledge” about how these systems can behave in non-academic settings,” Jackson added. “The amount of compute needed to reproduce the original results [for AlphaZero] is pretty high. I don’t remember the number off the top of my head, but it involved running about a thousand GPUs for a week. We were in a pretty unique position to be able to help the community try these models with our early access to the Google Cloud Platform’s TPU product, which was not yet publicly available.”
Implementing proprietary systems in open source is fraught with challenges, especially when there’s little public information to go on. Ideally, the code is available in addition to the data set used to train the system and what are called weights, which are responsible for transforming data fed to the system into predictions. But this isn’t often the case.
For example, in developing OpenFold, Ahdritz and team had to gather information from the official materials and reconcile the differences between different sources, including the source code, supplemental code, and presentations that DeepMind researchers gave early on. Ambiguities in steps like data prep and training code led to false starts, while a lack of hardware resources necessitated design compromises.
“We only really get a handful of tries to get this right, lest this drag on indefinitely. These things have so many computationally intensive stages that a tiny bug y can greatly set us back, such that we had to retrain the model and also regenerate lots of training data,” Ahdritz said. “Some technical details that work very well for [DeepMind] don’t work as easily for us because we have different hardware … In addition, ambiguity about what details are critically important and which ones are selected without much thought makes it hard to optimize or tweak anything and locks us in to whatever (sometimes awkward) choices were made in the original system.”
So, do the labs behind the proprietary systems, like OpenAI, care that their work is being reverse-engineered and even used by startups to launch competing services? Evidently not. Ahdritz says the fact that DeepMind in particular releases so many details about its systems suggests it implicitly endorses the efforts, even if it hasn’t said so publicly.
“We haven’t received any clear indication that DeepMind disapproves or approves of this effort,” Ahdritz said. “But certainly, no one has tried to stop us.”














 English (US) ·
English (US) ·