Что такое обработка естественного языка?
Обработка естественного языка (Natural Language Processing, NLP) — это набор методов, помогающих компьютерной системе понимать человеческую речь.
NLP является подразделом искусственного интеллекта. Это одна из сложнейших задач ИИ, не решенная в полной мере до сих пор.
Когда появился NLP?
Корни естественной обработки языка уходят в 1950 годы, когда известный английский ученый Алан Тьюринг опубликовал статью «Вычислительные машины и разум», предложив так называемый «Тест Тьюринга». Одним из его критериев является способность машины автоматически интерпретировать и генерировать человеческую речь.
7 января 1954 года ученые Джорджтаунского университета продемонстрировали возможности машинного перевода. Инженеры смогли перевести более 60 предложений с русского языка на английский в полностью автоматическом режиме. Это событие положительно повлияло на развитие машинного перевода и вошло в историю, как Джорджтаунский эксперимент.
В 1966 году американский информатик немецкого происхождения Джозеф Вейценбаум в стенах Массачусетского технологического института разработал первый в мире чат-бот «Элизу». Программа пародировала диалог с психотерапевтом, используя технику активного слушания.
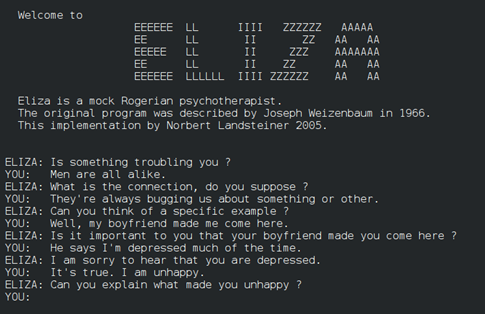 Диалог с «Элизой». Данные: Википедия.
Диалог с «Элизой». Данные: Википедия.По большому счету, система перефразировала сообщения пользователя, чтобы создать видимость понимания сказанного. Однако, на самом деле, программа не вникала в суть диалога. Когда она не могла найти ответ, то обычно отвечала «I see» («Понятно») и переводила беседу в иное русло.
В том же году Консультативный комитет по автоматической обработке языков (ALPAC) выпустил отчет и пришел к выводу, что десятилетние исследования не оправдали ожиданий. В результате финансирование машинного перевода резко сократилось.
В течение последующих десятилетий прорывов в области NLP не наблюдалось, вплоть до возникновения первых алгоритмов машинного обучения в 1980 годах. Примерно в это же время появились системы статистического машинного перевода, благодаря чему исследования возобновились.
Бум в области обработки языка пришелся на 2010 годы, когда стали развиваться алгоритмы глубокого обучения. В этот период появилось множество разработок, которыми мы пользуемся и сегодня, такие как чат-боты, автокорректоры, голосовые помощники и прочие. Чаще всего для решения этих задач стали использовать рекуррентные нейронные сети.
Очередная революция в NLP-системах произошла в 2019 году, когда OpenAI презентовала языковую модель Generative Pre-Trained Transformer 2, или GPT-2. В отличие от существующих генераторов, эта нейросеть умела создавать длинные строки связанного текста, отвечать на вопросы, сочинять стихи и составлять новые рецепты.
Спустя год OpenAI показала новую версию GPT-3, а крупные технологические компании одна за другой стали демонстрировать собственные разработки в области крупных языковых моделей.
Как работают NLP-системы?
Для ответа на этот вопрос необходимо обратить внимание на то, как естественный язык используем мы, люди.
Когда мы слышим или читаем какую-либо фразу в нашем подсознание происходит одновременно несколько процессов:
- восприятие;
- понимание смысла;
- реагирование.
Восприятие — это процесс перевода сенсорного сигнала в символьный вид. Например, мы можем услышать конкретное слово или увидеть его написание разными шрифтами. Любой из этих видов получения информации необходимо преобразовать в единый: написанные буквами слова.
Понимание смысла — это самая сложная задача, с которой не всегда справляются даже люди со своим естественным интеллектом. Из-за незнания контекста и неправильной интерпретации фразы могут возникать различные конфузы, а иногда и серьезные конфликты.
Например, в 1956 году в разгар холодной войны между СССР и США глава советского государства Никита Хрущев произнес речь, в которой прозвучала фраза «Мы вас похороним». Американцы восприняли сказанное слишком буквально и расценили это как угрозу ядерного нападения. Хотя на самом деле, Хрущев всего-то имел в виду, что социализм переживет капитализм, а сама фраза является интерпретацией тезиса Карла Маркса.
Инцидент быстро перерос в международный скандал, за что советским дипломатам и генсеку компартии пришлось извиниться.
Именно поэтому очень важно правильно понимать смысл речи, контекст сказанного или написанного, чтобы не допускать таких ситуаций, влияющие на жизни людей.
Реакция — результат принятия решения. Это довольно простая задача, требующая формирования набора возможных ответов на основании смысла воспринятой фразы, контекста и, возможно, каких-то внутренних переживаний.
Алгоритмы обработки естественного языка работают по точно такому же принципу.
Восприятие — это процесс перевода входящей информации в понятный для машины набор символов. Если это текст у чат-бота, то такой входящий набор будет непосредственным. Если это аудиофайл или рукописный текст, то для начала его нужно перевести в удобный вид. С этим успешно справляются современные нейронные сети.
Задачу реагирования на текст также успешно решили путем взвешивания альтернатив и сравнивания результатов друг с другом. Для чат-бота это может быть текстовый ответ из его базы знаний, а голосового помощника — совершение действия с каким-то объектом умного дома, например, включение лампочки.
С пониманием же дела обстоят несколько по-другому и этот вопрос следует рассмотреть отдельно.
Как ИИ-системы понимают речь?
На сегодня распространены такие виды анализа при решении задач понимания языка:
- статистический;
- формально-грамматический;
- нейросетевой.
Статистический широко применяется в сервисах машинного перевода, автоматических рецензентах и некоторых чат-ботах. Суть метода заключается в «скармливании» модели огромного количества массива текстов, в которых установлены статистические закономерности. Потом такие модели используются для переводов текстов или генерирования новых, иногда и с пониманием контекста.
Формально-грамматический подход представляет собой математический аппарат, позволяющий точно и однозначно определить смысл фразы на естественном языке настолько, насколько это возможно для машины. Однако это не всегда удается сделать, так как смысл некоторых фраз неясен даже людям.
Для развитых языков вроде русского или английского точное и детальное описание речи в математических терминах является крайне сложной проблемой. Поэтому формально-грамматический подход чаще используется для синтаксического анализа искусственных языков, из которых специально удаляют неоднозначности при проектировании.
В нейросетевом подходе для распознавания смысла входной фразы и генерации реакции ИИ-системы используются нейронные сети глубокого обучения. Они обучаются на парах стимул-реакция, где стимулом является фраза на естественном языке, а реакцией — ответ ИИ-системы на нем же или какие-либо действия ИИ-системы.
Это очень перспективный подход, но он обладает всеми отрицательными качествами нейронных сетей.
Для чего используются NLP-системы?
Системы обработки естественного языка используются для решения множества задач, начиная от создания чат-ботов и заканчивая анализом огромных текстовых документов.
К основным задачам NLP относятся:
- анализ текста;
- распознавание речи;
- генерация текста;
- трансформация текст в речь.
Анализ текста – это интеллектуальная обработка больших объемов информации, целью которой является выявление закономерностей и сходств. Он включает в себя извлечение данных, поиск, анализ высказываний, вопросно-ответные системы и оценка тональности.
Распознавание речи — это процесс преобразования текстовых файлов или голоса в цифровую информацию. Простой пример: при обращении к Siri алгоритм в режиме реального времени распознает речь и преобразует ее в текст.
Генерация текста — это процесс создания текстов с использованием компьютерных алгоритмов.
Преобразование текста в речь — это процесс, обратный распознаванию речи. Примером может служить чтение информации из интернета голосовыми помощниками.
Где применяют системы естественной обработки языка?
Существует множество способов использования технологий NLP в повседневной жизни:
- почтовые службы используют байесовскую фильтрацию спама, статистический метод NLP, который сравнивает входящие сообщения с базой данных и идентифицирует нежелательные письма;
- текстовые редакторы вроде Microsoft Word или Google Docs используют обработку языка для исправления ошибок в словах не только грамматических, но и контекстных;
- виртуальные клавиатуры в современных смартфонах могут предугадывать последующие слова в контексте предложения.
- голосовые помощники вроде Siri или Google Assistant могут узнавать пользователя, выполнять команды, трансформировать речь в текст, осуществлять поиск в интернете, управлять устройствами умного дома и многое другое;
- приложения специальных возможностей на ПК и смартфонах могут озвучивать текст и элементы интерфейса для слабовидящих людей благодаря алгоритмам синтеза речи;
- языковые модели с огромным количеством параметров вроде GPT-3 или BERT могут генерировать тексты различной длины в разнообразных жанрах, помогать осуществлять поиск и предсказывать предложение по нескольким первым словам;
- системы машинного перевода используют статистические и языковые модели для перевода текстов из одного языка в другой.
Какие трудности возникают при использовании NLP-технологий?
Часто при решении задач NLP используются рекуррентные нейросети, обладающие рядом недостатков, среди которых:
- последовательная обработка слов;
- неспособность удержать в памяти большой объем информации;
- подверженность проблеме исчезающего/взрывающегося градиента;
- невозможность параллельной обработки информации.
Помимо этого, популярные методы обработки часто ошибаются в понимании контекста, что требует дополнительной осторожной настройки алгоритмов.
Большинство этих проблем решают большие языковые модели, однако и с ними есть ряд сложностей. В первую очередь — их доступность. Большую языковую модель, по типу GPT-3 или BERT, сложно натренировать, однако крупные компании все чаще стали выкладывать их в открытый доступ.
Также многие модели работают лишь с популярными языками, игнорируя нераспространенные наречия. Это влияет на способность голосовых алгоритмов распознавать различные акценты.
При обработке текстовых документов посредством технологии оптического распознавания символов многие алгоритмы до сих пор не могут справиться с рукописными шрифтами.
Помимо технологических недостатков, NLP также могут использовать в злонамеренных целях. Например, в 2016 году компания Microsoft запустила в Twitter чат-бота Tay, который обучался общению на примере своих собеседников-людей. Однако спустя всего 16 часов компания отключила робота, когда он стал публиковать расистские и оскорбительные твиты.
В 2021 году мошенники из ОАЭ подделали голос руководителя крупной компании и убедили банковского работника перевести $35 млн на их счета.
Аналогичный случай произошел в 2019 году с британской энергетической компанией. Мошенникам удалось украсть около $243 000, выдав себя за директора компании с помощью поддельного голоса.
Большие языковые модели могут использоваться для массовых спам-атак, домогательств или дезинформации. Об этом предупредили создатели GPT-3.Они также сообщили, что их языковая модель подвержена предвзятости к определенным группам людей. Однако в OpenAI сообщили, что уменьшили токсичность GPT-3, а в конце 2021 года предоставили доступ к модели широкому кругу разработчиков и разрешили кастомизировать ее.
Подписывайтесь на новости ForkLog в Telegram: ForkLog AI — все новости из мира ИИ!














 English (US) ·
English (US) ·