
Что такое рекомендательные системы?
Рекомендательные системы — это алгоритмы, подбирающие релевантные товары и услуги на основе данных о пользователе.
Технология является одним из подразделов машинного обучения.
Когда появились рекомендательные системы?
Рекомендательные системы появились относительно недавно. В 1990 году технологию впервые упомянул шведский ученый Юсси Карлгрен, описав ее как как «цифровую книжную полку». Эта работа легла в основу его будущих исследований.
В 2000 годах алгоритмы рекомендаций начали проникать в сферу электронной коммерции. Одним из пионеров в этой области является онлайн-ритейлер Amazon.
В 2006 году компания Netflix, занимающаяся в то время прокатом DVD-дисков по подписке, запустила конкурс на лучший рекомендательный алгоритм с призовым фондом в $1 млн. Для его получения независимым разработчикам необходимо было улучшить точность алгоритма рекомендаций на 10%. В 2009 году приз вручили команде BellKor’s Pragmatic Chaos.
В 2010 годах рекомендательные системы появились в социальных сетях. На сегодня большинство популярных платформ отказались от использования хронологической ленты в пользу алгоритмической.
Как работают рекомендательные системы?
На сегодня используются два основных подхода в рекомендательных системах: коллаборативная фильтрация и модель, основанная на контенте.
Основной принцип коллаборативной фильтрации — генерировать рекомендации на основе данных о других пользователях с похожими интересами. Фильтрация бывает user-based и item-based.
Основная задача user-based алгоритма — найти пользователей, чьи интересы максимально похожи на основе потребленных ими продуктов и выставленных оценок. Допустим, Анна и Вадим купили сок, булочку и йогурт. Также известно, что Максим часто приобретает сок и булочки. Это значит, ему нужно порекомендовать купить йогурт.
Item-based рекомендации рассматривают задачу с противоположной стороны: найти похожие объекты и посмотреть, как их оценивали до этого. Попробуем выяснить, нравится ли Максиму йогурт. Мы знаем, что он любит сок и булочки. Йогурт, как продукт питания, обладает похожими характеристиками. Значит мы можем предположить, что этот товар понравится Максиму.
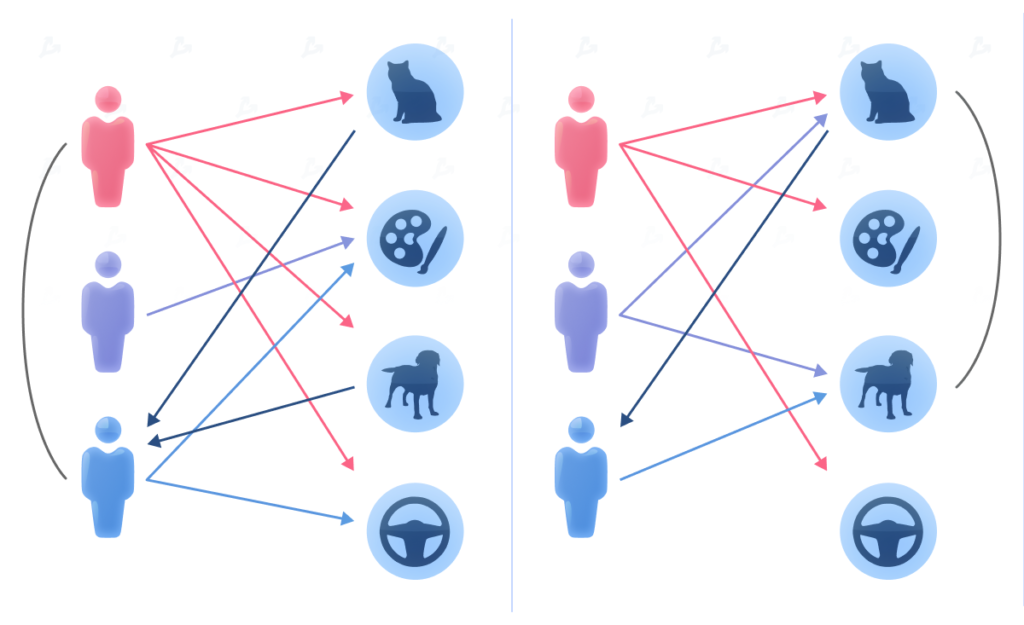 Логика определения похожести пользователей в user-based (слева) и item-based (справа) фильтрации.
Логика определения похожести пользователей в user-based (слева) и item-based (справа) фильтрации.Цель коллаборативной фильтрации — найти пользователя, оценившего конкретный объект, и рассчитать коэффициент корреляции векторов его оценок всех объектов в базе данных. Для этого часто используют метод k-ближайших соседей.
В центре модели, основанной на контенте, находится объект. Для работы алгоритма оценки пользователя не нужны. Модели важно знать любые свойства, характеризующие объект: автор, жанр, страна происхождения, производитель и т. д. При этом необходимо понимать, что не все из них релевантные для потребителя, поэтому стоит ограничится лишь основными атрибутами.
В последнее время основанные на контенте модели пользуются большой популярностью. Их не нужно долго обучать, разработчики могут сразу начать рекомендовать товары для пользователей.
Однако у этого метода есть и недостатки. Многие пользователи замечали, что после поиска определенного товара в Google, их начинала «преследовать» реклама с предложением приобрести этот товар в каком-нибудь интернет-магазине. Для уменьшения количества отрицательных отзывов о нерелевантности подобных объявлений, разработчики дополняют алгоритмы моделями, основанными на знаниях. Они также не опираются на оценки, а учитывают лишь профили пользователя и товара.
Как рекомендательные системы собирают данные?
Данные для рекомендательных алгоритмов могут собираться явным и скрытым способами.
К явным способам относятся запрос у пользователя оценить объекты по дифференцированной шкале, ранжировать их от лучшего к худшему, сравнить два похожих товара или составить список любимых объектов. Ключевой момент — пользователь понимает, что его данные используются алгоритмами и дает согласие на их обработку.
Во время скрытого способа посетители сайтов не всегда отдают себе отчет в том, что их действия могут использоваться рекомендательными системами. Сюда относятся файлы cookie, рекламные трекеры Google или Facebook, детальный анализ взаимодействия с видеороликами и прочее.
Как правило, правительства многих стран обязывают сайты оповещать посетителей о сборе таких данных. Однако у пользователей не всегда есть возможность отказаться от этого.
Где используются рекомендательные системы?
Как уже упоминалось, рекомендательные системы широко используются в электронной коммерции. С их помощью интернет-магазины могут советовать покупателям релевантные товары в блоке «Вам также может понравиться» или предлагать комплементарные продукты непосредственно в корзине. Также если товара нет на складе, алгоритмы могут найти аналоги.
В почтовых рассылках также часто используются персональные рекомендации.
Подобными алгоритмами пользуются ритейлеры вроде Amazon, Ozon или Wildberries.
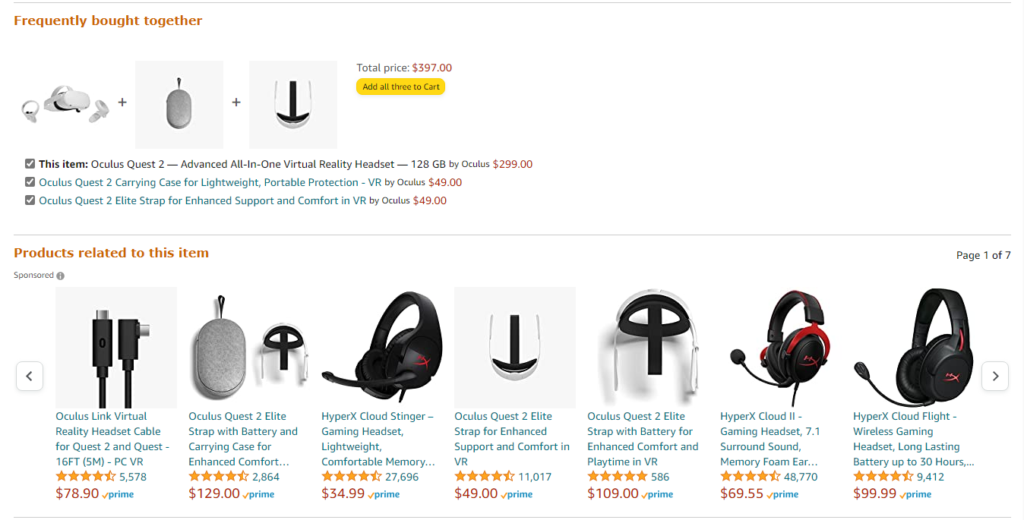 Рекомендации в карточке товара Amazon. Данные: Amazon.
Рекомендации в карточке товара Amazon. Данные: Amazon.Крупные стриминговые сервисы также используют рекомендательные системы. Среди них Netflix, Spotify, Apple Music, Яндекс.Музыка, YouTube, Megogo и прочие.
Алгоритмы рекомендаций широко используются и в социальных сетях. Facebook, Twitter, Instagram, ВКонтакте и другие уже на протяжении многих лет демонстрируют пользователям контент, собранный алгоритмами. Лишь немногие из них позволяют переключиться на хронологическую ленту.
Какие проблемы у рекомендательных систем?
Рекомендательные системы обладают рядом ограничений. Одним из них является проблема холодного старта — когда для работы алгоритма еще не накоплено достаточное количество данных. Это типичная ситуация для нового или непопулярного объекта, который оценило малое количество пользователей, или для неординарного потребителя, предпочтения которого сильно отличаются от среднестатистического пользователя.
В таких случаях рейтинги корректируют искусственно. Например, оценку вычисляют не как среднюю по позиции, а как сглаженную среднюю. При малом количестве отзывов рейтинг объекта будет тяготеть к некой «безопасной средней», а когда набирается достаточное количество реальных оценок, то искусственное усреднение отключается.
Другая проблема рекомендательных алгоритмов — предвзятость. Неточно настроенные алгоритмы, заложенные в них стереотипы, а также действия пользователей могут повлиять на ранжирование информации.
В 2021 году рекламные алгоритмы Facebook непропорционально показывали разные объявления о вакансиях мужчинам и женщинам. Инструмент автоматической обрезки фотографий для домашней ленты Twitter в большинстве случаев акцентировал внимание на молодых и стройных девушках.
В обоих случаях разработчики быстро исправили ошибки, однако не всегда это удается. С критикой работы рекомендательных алгоритмов постоянно сталкивается компания Google.
Например, результаты выдачи по поисковому запросу «спортсмены» и «спортсменки» сильно отличаются. В случае с мужчинами алгоритмы показывают статьи с профессиональными достижениями атлетов. Однако по отношению к женщинам система выдает различные рейтинги «привлекательности» и «сексуальности».
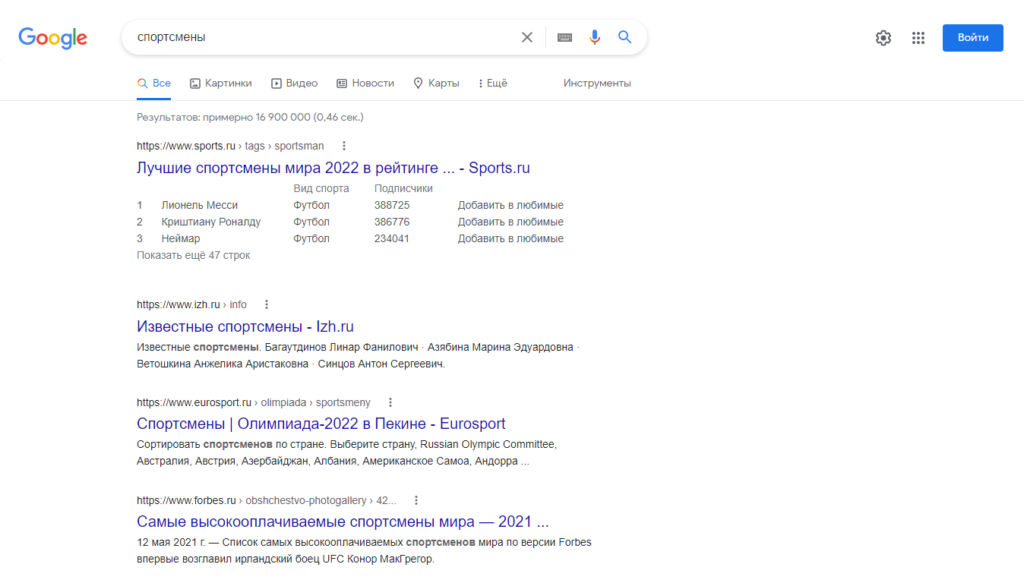
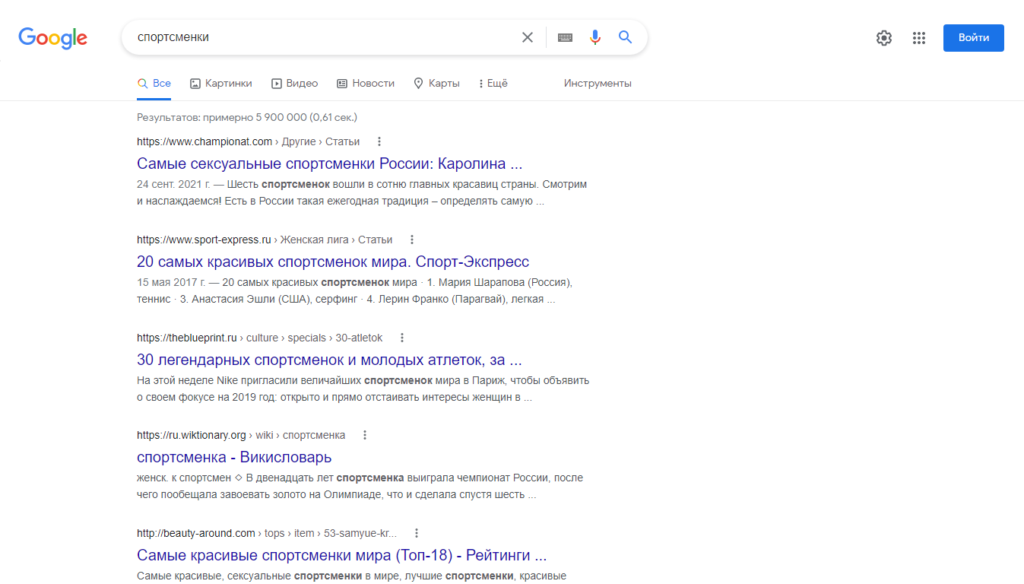
Влиять на поисковую выдачу могут не только пользователи, но и боты. В 2018 году пользователи Reddit провели намеренные манипуляции с алгоритмами Google, чтобы по запросу «идиот» отображалась фотография бывшего президента США Дональда Трампа.
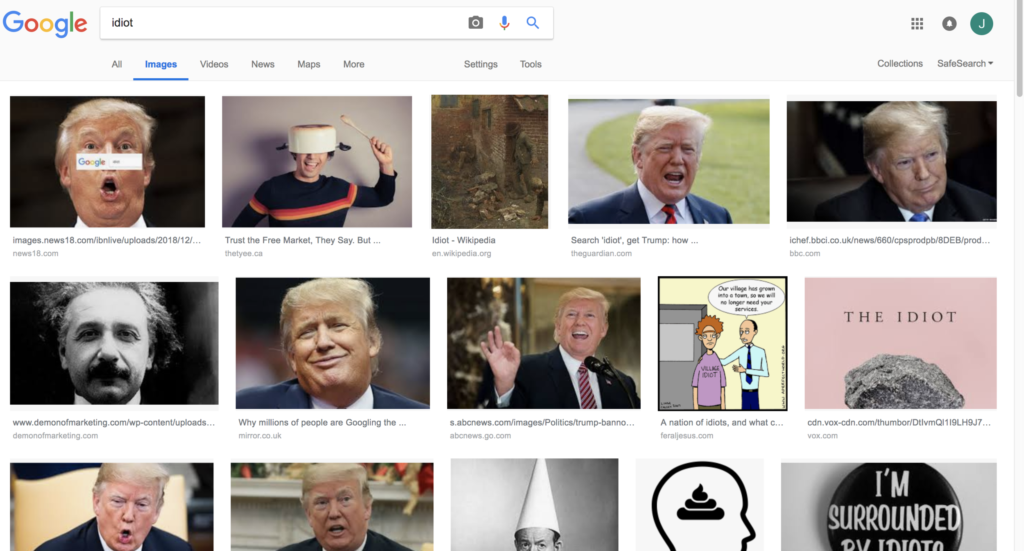 Дональд Трамп, попавший в выдачу по запросу idiot. Данные: Google.
Дональд Трамп, попавший в выдачу по запросу idiot. Данные: Google.Во время слушаний в Конгрессе по поводу инцидента генеральный директор корпорации Сундар Пичаи сообщил, что сотрудники компании не вмешиваются в ранжирование информации. По его словам, алгоритмы делают это самостоятельно, сканируя миллионы поисковых строк и ранжируя их по более чем 200 параметрам.
Предвзятостью алгоритмов могут пользоваться и разработчики рекомендательных систем. В октябре 2021 года бывшая сотрудница Facebook опубликовала документы, доказывающие намеренное использование «вредных» инструментов на площадке. По ее словам, топ-менеджмент знал, что алгоритмы проявляют нетерпимость по отношению к незащищенным слоям населения. Но компания не спешила устранять ошибки, так как такой контент сильнее вовлекал пользователей и увеличивал доходы компании за счет показа рекламы.
Подписывайтесь на новости ForkLog в Telegram: ForkLog AI — все новости из мира ИИ!














 English (US) ·
English (US) ·